
In the fast-paced world of software engineering, everyone’s searching for the ultimate shortcut. The one secret sauce that will let you skip all the hard work and dive straight into coding heaven. And when Google, the giant of the tech world, waves the flag for a particular approach, it’s easy to think you’ve found the golden ticket. But let me tell you, in the realm of Android app architecture, what seems like a shortcut might just lead you down a treacherous path. I’m talking about Google’s Guide to App Architecture, the so-called “Google architecture” – a roadmap that may look promising at first glance but is riddled with pitfalls. Buckle up, because we’re about to dive into the controversial territory of Android’s approach to app architecture, and you might not like what you find.
Introduction
I usually adhere to design philosophies like Clean Architecture, Onion Architecture, and DDD. These philosophies emphasize the importance of a dedicated domain or business layer where essential business rules are concentrated. These layered architectures are well-suited for complex applications but may seem excessive for simpler projects. As a result, it can be tempting to completely skip them, perhaps deluding oneself into thinking that any issues will be addressed later. This temptation is often amplified when a well-known company endorses such an approach as a best practice for one of its flagship platforms.
It should come as no surprise that many companies have ventured down this path, only to find that their codebase gradually becomes more challenging to maintain. Duplication starts to seep in, and adding complex features becomes increasingly painful.
Does this sound familiar? This was the situation with one of our projects. In this context, I present an architectural strategy aimed at rectifying these issues by emphasizing a more robust domain layer and facilitating the transition to a comprehensive layered architecture: Progressive domain model.
The Domain is Central
Clean Architecture and Onion Architecture endorse encapsulating business logic in the application’s heart, surrounded by layers each bearing specific tasks with clear delineations. This division fosters modularity and maintenance ease. Another core principle is the dependency rule; dependencies should point inwards, ensuring higher layers don’t rely on lower ones, resulting in a flexible, autonomous design.
Domain Layer in Android: The Missteps
Android’s Guide to App Architecture (some people call this “Google architecture”), as of September 2023, hints at an optional domain layer, placing necessary domain logic in view models that communicate directly with the data layer. This might suffice for basic apps, but for more convoluted applications, introducing a domain layer can decomplicate view models and reduce repetition. However, the official documentation’s portrayal of the domain layer depending on the data layer breaches the dependency rule. The absence of mention of domain models insinuates that data models (DTOs) might be domain models, leading to confusion.

Domain Layer in Android: The Correct Approach
I propose centering the domain concerning dependencies, aligning with the architectural patterns mentioned above.
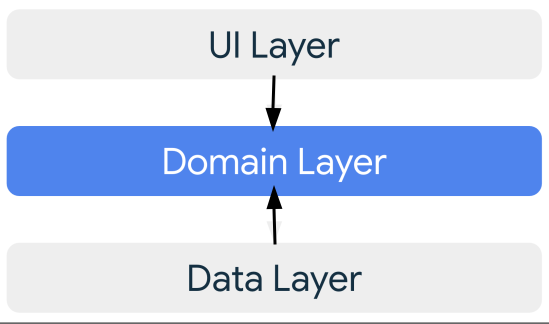
UI and Data should rely on the domain layer, which remains oblivious to other layers. As a result, the domain layer contains simple Java (POJO) or Koltin objects to formulate domain models, value objects, use cases, etc.
Employing dependency inversion lets us leverage data layer services. For instance, repositories are characterized as interfaces within the domain layer but realized in the data layer. Repository interfaces should exclusively rely on the domain layer. The data layer should also handle mapping between domain and data models.
While the merits of this structure are clear, the downside is the necessity of more initial coding. Often, early in a project, the demarcation between DTOs and domain models is so negligible that the effort feels pointless.
Progressive Domain Model
Assuming an application communicating with a remote service via REST API, using Android libraries like Retrofit and a parsing library (for example, Moshi), allows sophisticated DTOs and aggregates. Sometimes, these DTOs can be treated like domain models. But they aren’t. The crux is to employ DTOs as pseudo domain models until a transition to comprehensive domain models, truly plain DTOs, and mappers becomes inevitable.
However, a pivotal distinction is needed: these are domain models that incidentally function as DTOs, not vice-versa. The domain model role trumps the DTO one. Is like a hack we make to our domain models to also work as DTOs, but when circumstances demand, we should prioritize the role of the domain model over that of the DTO. Eventually, distinct sets for both domain models and DTOs might need creation, alongside associated mapping logic.
Refactoring Examples
The following examples have been adapted from real-world scenarios. We have recently begun implementing them in a real-world application with a substantial codebase, and the results have been highly promising.
Refactoring use cases with simple transformation logic
Suppose you have followed the advice outlined in the Android’s Guide to App Architecture. This suggests that the domain layer typically consists of use cases or interactors that encapsulate reusable logic. While there is nothing inherently wrong with this approach, sometimes it can lead to situations like the one described below.
For example, let’s consider the development of a home automation app where the device profiles are reported using a DTO like this.
@JsonClass(generateAdapter = true)
data class Device(
@Json(name = "id")
val id: String,
@Json(name = "modules")
val modules: List<Module>,
...
)
@JsonClass(generateAdapter = true)
data class Module(
@Json(name = "role")
val functions: List<Function>,
...
)As an example, consider a device like a smart power strip with multiple individually controllable sockets, where each socket may support functions such as on-off switching, power regulation (for tasks like light dimming), or a combination of both functions.
Now, let’s assume that multiple view models need to enumerate the functions of each module. Since device modules are accessed by index, in order to prevent crashes caused by out-of-bounds exceptions, the following use case has been developed:
class GetDeviceModuleUseCase() {
fun invoke(device: Device, index: Int = 0): List<Function> {
return try {
device.modules[index].functions
} catch (e: IndexOutOfBoundsException) {
emptyList()
}
}
}The view model willing to access the module’s functions will need to do something like:
class SomeViewModel @Inject constructor(
private val getDeviceModuleUseCase: GetDeviceModuleUseCase,
...
) : ViewModel() {
private fun doSomething() {
...
val functions = getDeviceModuleUseCase(device, moduleIndex)
...
}
...
}Not great. Just to access the module’s functions in a safe way we need to inject a use case and call it explicitly cluttering the logic.
This use case can be refactored as a Device function:
@JsonClass(generateAdapter = true)
data class Device(
@Json(name = "id")
val id: String,
@Json(name = "modules")
val modules: List<Module>,
...
) {
fun functions(moduleIndex: Int): List<Function>
get() = return try {
device.modules[moduleIndex].functions
} catch (e: IndexOutOfBoundsException) {
emptyList()
}
}Now, the use case has been removed, and the view model looks like this, making the code simpler and more expressive.
class SomeViewModel @Inject constructor(
...
) : ViewModel() {
private fun doSomething() {
...
val functions = device.functions(moduleIndex)
...
}
...
}Refactoring “impedance mismatches”
Sometimes, the de facto model represented by the DTOs does not always align with the optimal usage pattern for the view models. For instance, cWe’ve all been there: diving deep into the rabbit hole of modern architectural paradigms, clinging to dogmatic design principles, only to end up with an overengineered monstrosity for a project that needed a fraction of the complexity. The buzzwords are seductive – Clean Architecture, Onion, DDD. But do they always make sense? Perhaps not. Especially when the Android’s Guide to App Architecture, an authoritative voice for many, seems to flirt with practices that some would consider…heretical. In this post, I challenge the status quo, provoke the purists, and introduce a new way of thinking: the Progressive Domain Model. If you’ve ever felt the sting of overcomplication, or dared to question architectural sacred cows, then read on. The architectural enlightenment you’ve been seeking may just be a few scrolls away.onsider a different version of the home automation app in which a particular device is associated with a specific type:
@JsonClass(generateAdapter = true)
data class Device(
@Json(name = "id")
val id: String,
@Json(name = "device_type_id")
val typeId: String,
...
)
@JsonClass(generateAdapter = true)
data class DeviceType(
@Json(name = "id")
val id: String,
@Json(name = "modules")
val modules: List<Module>,
...
)While the DeviceType describes a specific type of product, like a ‘Four socket power strip‘, a Device is a particular instance of that product.
One of the advantages of this approach is that common device properties, such as the list of modules, can be stored in the DeviceType and shared among multiple instances of the same device type, thereby conserving bandwidth.
However, if your application logic within the view models is tightly coupled with these DTOs, you would need to first retrieve the DeviceType using its ID to obtain the modules of a specific Device.
class SomeViewModel @Inject constructor(
private val getDeviceTypeByIdUseCase: GetDeviceTypeByIdUseCase,
...
) : ViewModel() {
private fun doSomething() {
...
val deviceType = getDeviceTypeByIdUseCase(device.typeId)
...
}
...
}Once again, we find ourselves having to complicate the code, resulting in unnecessary clutter, all for the sake of accessing a property that is closely related to the Device from the view model’s perspective, because it doesn’t align with how the API functions.
As part of the refactoring process, we aim to include a complete DeviceType within the Device. This way, there won’t be a need for an additional use case, and the device type can be accessed directly, like this:
val deviceType = device.typeThe refactor involves renaming Device as DeviceDto and replacing it with a plain object named Device that will serve as a standard domain model.
data class Device(
val id: String,
val type: DeviceType,
...
)
@JsonClass(generateAdapter = true)
data class DeviceDto(
@Json(name = "id")
val id: String,
@Json(name = "device_type_id")
val typeId: String,
...
)The repository has also been updated to correctly construct the Device object, including the DeviceType instance (some details are omitted for simplicity).
class DeviceRepository {
fun byId(id: String): Device {
val deviceDto = deviceDataSource.byId(id)
val deviceTypeDto = deviceTypeDataSource.byId(deviceDto.typeId)
return Device(
id = deviceDto.id,
type = deviceTypeDto,
....
}
}The solution involves introducing additional code, including mapping logic that might be considered boilerplate, which needs to be created and maintained. While it is indeed extra work, in my experience, this additional logic often handles straightforward transformations (and can be generated efficiently with AI tools) and resides in just one location, making its maintenance simpler.
It’s worth noting that the Device still references the original DeviceType without any alterations. In other words, breaking down the containing class (Device) doesn’t necessarily require making changes to the contained classes. This is why I refer to this approach as a progressive domain model.
Conclusions
The world of application architecture is diverse, with strategies like Clean Architecture and Onion Architecture favoring the separation of concerns and a well-defined domain layer.
Coupling the presentation layer with the data layer might offer rapid prototyping, especially for smaller projects. Such a structure lends itself to quicker development, requiring less code and fewer abstractions. However, the caveats surface when the project scales or requires more intricate business logic. The entanglement of view models and DTOs can create technical debt, hinder the introduction of new features, and lead to more complex refactoring processes.
If you’re starting a project from scratch, I’d recommend doing things right from day zero. However, if you’ve already adopted the so-called “Google architecture” and are now facing challenges in evolving the project, the approach described here can certainly help you progressively migrate to a cleaner architecture.