
In this post, a Clean Architecture implementation for Android using the Kotlin language is presented and discussed. An example App is also provided to support the discussion. The full source code can be downloaded from GitHub.
Recently I faced the challenge of starting from scratch a new Android application for a customer. Like many other Apps, it relies on a backend service to perform its job. I wanted to adopt the best tools and practices available. In this case, I’ve chosen the following technologies (I assume the reader has a basic knowledge of them):
- Kotlin as the programming language
- Reactive programming with ReactiveX (RxJava2)
- Dependency injection with Dagger2
- Unit tests with JUnit and Mockito
Of course, as software should remain soft and this is only our starting point, we expect the project to evolve, but I hope these foundations are robust enough to build on. Time will tell and sure there are many lessons yet to be learned.
I want to thank Fernando Cejas for his two great posts on the subject: Architecting Android…The evolution and Architecting Android…Reloaded which I used as a base for this work. I highly recommend checking them out.
Our Android incarnation of the Clean Architecture
The Clean Architecture was proposed by Robert C. Martin (Uncle Bob) and as with many other architectures, one of the main goals is the separation of concerns into layers. The benefits of adopting an architecture like this include scalability, maintainability, modularization, no coupling with specific data sources, storage methods, frameworks, etc.
In this case, I adopt a four-layer architecture:
- Domain. The business rules.
- Application. Application-specific rules.
- Presentation. What you see: fragments, activities, custom views, etc. and how the UI behaves.
- Data. Persistence, networking, communications, etc.
Additionally, we might think of an additional layer, the infrastructure, that includes the Android framework and other support libraries.
Why four layers?
Some projects merge both the domain and the application layer in a single tier that calls domain. I think that is fine but, for learning purposes, I believe is clearer to make the distinction between domain and application. For instance, when dealing with some errors, like network or server errors, definitively, these are not part of the domain model, are not part of our “business”. However, this is something you need to manage, often making the user aware of these conditions, and thus it fits nicely in the application layer.
The domain layer
The dependency rule of the Clean Code architecture states that in the core of the application is the domain and that this layer has no outwards dependencies. In other words, classes in the domain layer are pure Java (or Kotlin) classes with no imports of the Android framework or external libraries. To be more precise, these classes may have dependencies on the data injection library and to RxJava2 (you might think of these libraries as an extension of the programming language), but that’s it.
The domain layer is composed of model classes with identity or without identity (the latter are also called value objects), and domain-specific functions. These represent the business rules of your application and encapsulates the most high-level data and rules of the application.
The domain functions or domain services as they are called in DDD (not to be confused with Android services) embody those operations that do not conceptually belong to any specific entity (or value object) class.
The application layer
This layer contains application-specific logic. In particular, it implements the use cases through the interactors. Interactors rely on the model layer to provide their services but are completely agnostic about a particular database, transmission channels, storage formats, and so. We also put in this layer authentication and authorization logic and those exceptions that are part of the operation of the application such as network and server errors.
The presentation layer
Inside this, we deal with the interaction between the app and the user. To do so, we adopted the Model Presenter View (MPV) as a general pattern. In this pattern, the presenter adopts the role of intermediary between the domain (and application layer) and views.
View classes should be as simple as possible, i.e. just passive objects that display information on the screen and capture and translate user actions to the presenter. Doing this way, additional logic for the presentation is keep inside the presenter which makes it easier to unit tests.
Optionally, a model-view could be used between the view and the presenter. For instance, imagine a form with dozens of fields some of which are formatted according to the current locale. Using a model-view class helps us to deal with the specific data transformations outside of the view code (making it easier to test such logic) and saving many function members on the interface of the view.
The data layer
This layer usually provides the implementation of the repositories to work against a database, a network connection, or a set of local JSON files, for instance. Data is converted between the model layer to and from specific representations suitable for storage or transmission.
Note that the other layers must not know anything about the details on this layer, so that some parts might change, for instance, to add support to an updated version of the format of the data provided by the backend without disturbing the rest of the application.
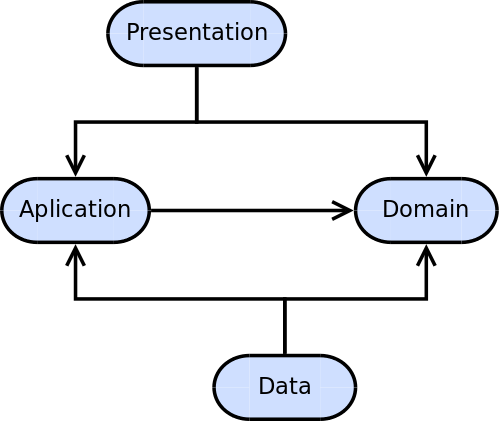
The drawing depicts the direction of the dependencies between each layer. So, the domain layer does not have any outward dependencies, whereas the presentation and data layer is dependent on the application and domain layers.
The natural execution flow goes from top to bottom and from left to right in this diagram, which contrasts with the direction of the dependencies.
Take for instance a request made from the presentation layer to retrieve and display some piece of information that happens to live in a database. The command the user issues travels from the presentation layer to an interactor inside the application layer which ends up asking the data layer for the required information. The first layer cross is natural, it just consists of a call to a method in the presentation layer. However, the next layer cross, from the application layer to the data layer, works against the direction of the dependencies.
The dependency inversion principle
How can we keep those dependencies and, at the same time, perform a method call from the application layer to the data layer? This can be solved using the Dependency Inversion Principle. In Kotlin we just can create an interface in the application layer which declares the methods expected to be called and provide an implementation of that interface inside the data layer that actually performs the query to the database. Such a query most likely will return a dataset, hashmap, or some sort of data structure representing the rows in the database. It is also the responsibility of the data layer to transform such data into one or more domain models so that the dependency rules are never broken.
Sample App: Clean Architecture Rocks
The app built here consists of two views, one with a list of rock bands and the other with the information of a specific band including the list of studio albums. When tapping on an album, YouTube app is opened searching for the specific album of the band.
You might find the source code on GitHub.
Let’s see the code!
Let’s start with the top-level directory structure which the first thing you encounter when you open the project.

It shows the four (five, taking into account infrastructure) layers described above in the form of several packages. Certainly, it does not reveal the intention of the application, it just screams “four-layer architecture”. Fernando’s latest post, also suggests organizing packages by features, not layers. I appreciate the advantages of organizing the project folders around features, but I think adopting such an approach requires a high degree of discipline among the team. In contrast, the layer-based organization helps to put everything in its place.
Domain classes
In our example app, which only deals with data retrieval and presentation, domain classes are basically data structures. But these might also include domain-specific validation code and other functions to properly manage its state.
data class BandDetails(
val id: Int,
val name: String,
val genre: String?,
val description: String?,
val foundation_year: Int?,
val picture: URL?,
val albums: List<Album>) {
}
Application classes
The contents of the application package are shown in the image below.
These include exceptions that should be explicitly managed, interactors (use cases), navigation stuff, interfaces for the repositories (used by interactions), and a couple of services for formatting error messages and managing authentication (the latter consist of a dummy implementation and is left as an exercise for the reader to complete it).
About the navigation package, somebody might argue that these classes have dependencies on the Android framework and I’d better move to the infrastructure folder. On the other hand, the navigator might contain some application-specific logic that belongs to the application layer. In an attempt to “fix” this, we would refactor the navigator to extract the navigation rules in one application class and move the rest of the code to the infrastructure layer. But perhaps this a bit overkill. Thus, I decided to leave as is. What do you think?
Interactors and repositories
In our example app, interactors end up performing a network request to fetch data, which is a fairly common scenario. If we perform this operation in the main thread, the whole App will become unresponsive until the request is completed thus deteriorating the user experience. To avoid this, we need some kind of asynchronicity between the request and the response of our network calls and other I/O operations. In our context, it seems that the most widely used approaches are based on RxJava and Kotlin’s coroutines. The discussion about the pros and cons of these technologies is beyond the scope of this post. Suffice to say that I opted for RxJava because we plan to use it beyond performing network requests, but in fact, there is no dichotomy between both solutions, both can be used in the same application.
Here is how the UseCase class, used as the base for the interactors, looks like:
abstract class UseCaseSingle<T, Params>
constructor (private val schedulersProvider: SchedulersProvider)
: UseCase() {
abstract fun buildUseCaseSingle(params: Params): Single<T>
fun execute(observer: DisposableSingleObserver<T>, params: Params) {
val observable = buildUseCaseSingle(params)
.subscribeOn(schedulersProvider.getIOScheduler())
.observeOn(schedulersProvider.getUIScheduler())
addDisposable(observable.subscribeWith(observer))
}
}
In this case, we use the Single class from RxJava (as opposed to Observable) which is well-suited when a single asynchronous response is required, i.e. the request either returns a valid result or an error. The entry point for the use case is the function execute which expects the single observer implementation (i.e. the listener) and the required parameters (if any) for the request.
The following class implements a specific interactor that retrieves the band details given its ID. It only has to override the buildUseCaseSingle member function performing the actual request, which is simply delegated to the repository.
class GetBandDetails
@Inject constructor(private val bandRepository: BandRepository,
schedulersProvider: SchedulersProvider)
: UseCaseSingle<BandDetails, Int>(schedulersProvider) {
override fun buildUseCaseSingle(params: Int): Single<BandDetails> =
bandRepository.bandDetails(params)
}
This is the BandRepository interface:
interface BandRepository {
fun bands(): Single<List<Band>>
fun bandDetails(bandId: Int): Single<BandDetails>
}
It represents the contract the data layer must fulfill. Note how the dependency inversion works here. This interface is defined inside the application layer and this is all interactors know about how to perform a request. There is no reference to the data layer where the actual implementation lives. In other words, the data layer depends on the application layer and domain layers but not the other way round.
Another advantage of using this approach is that the implementation of the repository may change at will. For example, for development or testing purposes, specific implementations could be provided without having to rely on the production environment for reproducing certain working conditions.
Interactor client code and presentation layer
In our example project, interactors are used from the presentation layer to retrieve data about the rock bands. Here is how the presenter of the band details View looks like:
class BandDetailsPresenter
@Inject constructor(private val getBandDetails: GetBandDetails,
private val errorFormatter: ErrorMessageFormatter) {
fun init(view: BandDetailsFragment, band: BandViewEntity) {
getBandDetails.execute(object : DisposableSingleObserver<BandDetails>() {
override fun onSuccess(bandDetails: BandDetails) =
view.render(BandDetailsViewEntity.from(bandDetails))
override fun onError(e: Throwable) {
view.notify(errorFormatter.getErrorMessage(e))
view.close()
}
},
band.id)
}
fun onAlbumClicked(album: AlbumViewEntity) {
// add your code here
}
}
The init function is called from the view whenever it is ready, which in turn requests detailed information about the band by calling the execute member function of the GetBandDetails interactor. A DisposableSingleObserver implementation is provided which implements two functions, onSuccess and onError, which render the receiver data or show an error message respectively.
The presenter also adopts the role of controller, the function onAlbumClicked is called by the view whenever an album is clicked by the user to react accordingly, for instance, launching Spotify to start playing the selected album.
Data layer classes
These are the contents of the data package:
Inside the net package, we have the implementation of BandsRepository and the DTOs.
The following code is the DTO used to fetch the band details:
data class BandDetailsEntity @JsonCreator constructor(
@JsonProperty("id") val id: Int,
@JsonProperty("name") val name: String,
@JsonProperty("genre") val genre: String?,
@JsonProperty("description") val description: String?,
@JsonProperty("foundation_year") val year: Int?,
@JsonProperty("picture") val picture: String?,
@JsonProperty("albums") val albums: List<AlbumEntity>) {
fun toBandDetails(): BandDetails =
BandDetails(id, name, genre, description, year,
if (picture == null) null else URL(picture), albums.map { it.toAlbum() })
}
As in many apps, data travels the wire encoded as a JSON string. These annotations tell Jackson, how to serialize and to deserialize to and from JSON. Why Jackson instead of Google’s Gson? It is a matter of personal taste, but when I first started using the Gson parser I found that it skipped many validation steps, among which, setting null to non-nullable Kotlin fields. And, by default, preventing the deserialization of fields not labeled with @JsonProperty. I personally like tools that help me catch this kind of silly errors as soon as possible, and thus I’ve chosen Jackon.
The DTO also contains a function to convert the object to a domain object. The dependency of this class on the model class is perfectly fine.
Finally, there are the REST API created with Retrofit and the band repository:
internal interface BandsApi {
companion object {
private const val PARAM_BAND_ID = "bandId"
}
@GET("bands.json") fun bands(): Single<List<BandEntity>>
@GET("band_{$PARAM_BAND_ID}.json")
fun bandDetails(@Path(PARAM_BAND_ID) bandId: Int): Single<BandDetailsEntity>
}
And here is the implementation of such API:
@Singleton
class BandsApiService
@Inject constructor(retrofit: Retrofit) : BandsApi {
private val musicApi by lazy { retrofit.create(BandsApi::class.java) }
override fun bands(): Single<List<BandEntity>> =
musicApi
.bands()
.onErrorResumeNext { error: Throwable -> Single.error(translate(error)) }
override fun bandDetails(bandId: Int): Single<BandDetailsEntity> =
musicApi
.bandDetails(bandId)
.onErrorResumeNext { error: Throwable -> Single.error(translate(error)) }
private fun translate(throwable: Throwable): Throwable =
when(throwable) {
is JsonMappingException -> ServerErrorException(throwable)
is HttpException -> ServerErrorException(throwable)
else -> throwable
}
}
Note how here some specific errors are translated into application layer errors.
Infrastructure stuff
Inside this package, there is a miscellany of classes dealing with platform-specific or configuration-specific duties among which some base classes for fragments and activities, a few extension functions, and dependency injection related stuff. Most application configuration is done inside ApplicationModule class.
Don’t forget the tests!
I hope in 2020 in longer necessary to remind you that production code requires its corresponding unit tests. I try to write unit tests for everything except pure date classes and (dummy) views. No integration nor instrumented tests have been attempted in this project. However, I’ve written a basic test for the network API using a mocked web server. The intention here is to make sure that for specific JSON samples everything (read, my code) works as expected.
Conclusion
I presented an implementation for Android of the Clean Architecture based on four main layers relying on well-known and mature technologies such as Kotlin, Dagger 2, and RxJava 2. Surely this approach is over-engineered for a simple App like the one I presented as an example. But the point here is to establish the foundations for an application and a team that will grow over time.
The demo project and the approach presented here are far from perfect and might not suit your particular case, but I hope at least helps you to learn something. Feel free to leave your comments below or send your PR on GitHub.
This is genuinely a clean and concise implementation and a solid foundation for not only an MVP but also a complex app. Keep the good work, I think you can always customize it depending on various projects requirements.
Thank you!!1